Optimizations on Embedded Microcontrollers
This page is intended to be a growing collection of notes about how to optimize programs intended for embedded microcontrollers, where RAM memory and FLASH can be limited.
This page will forever be a work in progress. Last updated February 28th, 2022.
Table of Contents
General Notes
Optimize For What?
Things one can optimize for:
- Cost
- Execution Speed
- Latency
- Jitter
- RAM Usage
- FLASH Usage
- Readability
Cost can refer to the BOM cost of the microcontroller itself but keep in mind that it can also refer to the cost of engineering the product and developing the firmware for it. Does it make sense to save a few cents (or dollars, or your favorite currency) by specifying a very limited microcontroller when that decision might lead to a significantly more complex and expensive firmware development effort? BOM cost is recurring whereas engineering cost is NRE, so the answer to that question might depend largely on the expected production quantity. If the product is likely to see production of millions of units, then yes, every cent saved on the BOM translates to big bucks. But if the product is likely to see low production numbers in the hundreds to thousands, then the cost of firmware development may be more significant.
Readability refers to how readable the software code is. Sometimes, optimizations meant to squeeze a little more performance out of a microcontroller can result in code that is difficult to understand and maintain. Before doing an optimization, ask whether the code will be made less readable and whether the increased engineering burden is worth the optimization it may produce.
In an ideal world, one would want minimum Cost, maximum Execution Speed, minimum Latency, minimum Jitter, minimum RAM Usage, and minimum FLASH usage. Alas, this is not an ideal world, so software optimization is a balancing act in which one must make various trade-offs. For example, execution speed can often be increased at the expense of larger memory requirements for things like lookup tables, which may translate to a microcontroller with a larger RAM, which might translate to higher BOM cost. Therefore, before one can begin optimizing, one must have a good idea of the design requirements and set reasonable expectations.
Knowing When To Start
Donald Knuth of The Art of Computer Programming fame is credited with coining the phrase "premature optimization is the root of all evil" (see Structured Programming with go to Statements, Knuth 1974). The interpretation of that statement is left as an exercise for the reader.
Knowing When To Stop
When one bakes a cake, one must know when to take it out of the oven. Leave it in for too long and the cake will become a burnt mass of something inedible. The same law applies to optimization. Stop when the objectives have been achieved.Specific Notes
Without further ado, here are some specific notes.
Floating Point Math
There are engineers who like to say, "Never use floating point!" But I disagree. I'm not suggesting to do the opposite, which is to always use floating point, but I do advocate a more considered approach. Although floating point does have its well-known limitations, such as numerical properties that make floating point numbers behave quite differently than ℜ (real numbers in math), they can often simplify programming in ways that turn long-winded complicated code into something readable, and may even perform better. In contrast to fixed point, which often requires software routines, floating point can actually offer faster performance on microcontrollers that offer a floating point unit (FPU). But it is important to work within the limitations of that FPU.
Avoiding double-precision operations on microcontrollers with single-precision floating point units
I recently worked on a project that targets a STM32G4-family microcontroller, whose core is a member of the ARM Cortex M4F family, which offers a single-precision FPU. This means that floating point operations are done in hardware rather than software, which saves execution time as a hardware FPU is obviously faster than software routines. It also saves code space since the software routines are not needed.
I was careful to ensure that all floating point operations used only single-precision values. I was surprised, therefore, to learn that double-precision software routines were included in the FLASH image, taking up valuable space and undoubtedly slowing down performance wherever double-precision math was used.
How did I learn this? In STM32CubeIDE, there is a Build Analyzer tab which contains a view called Memory Regions and another view called Memory Details. (The information shown in these views is probably parsed from a map file produced by the linker at build time, but I have not yet investigated whether that is true.) Memory Regions is basically a summary with nice bar graphs showing the percent usage of RAM and FLASH, whereas Memory Details shows how the individual sections have been mapped by the linker.
Since I always build with -ffunction-sections and -fdata-sections for the compiler and -Wl,--gc-sections for the linker, each function and variable get their own section, allowing the linker to discard unused code and data at the granularity of individual functions and variables. (Without these options, the granularity is at the module level, so if a file contains a thousand functions and the program uses one of them, all thousand functions will be linked!) It also means that the linker map file and the Memory Details view can show how much each function takes up.
Before:
This is what the Memory Regions view showed when I built the firmware: Ignore the RAM usage of 4.93% but note that the FLASH usage was 24.22%.

And this is what the Memory Details view showed:
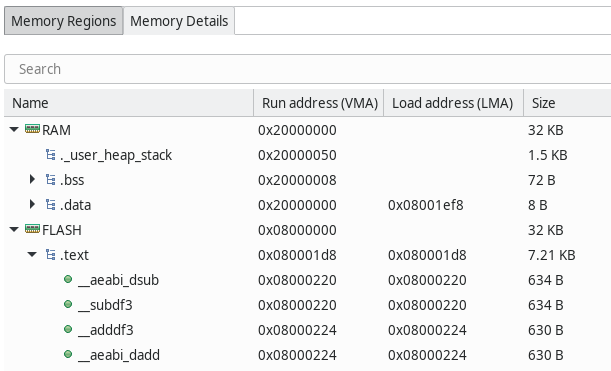
Note the four functions __aeabi_dsub, __subdf3, __adddf3, and __aeabi_dadd, each of which consumed 630 or 634 bytes. In a microcontroller with 32 KB of FLASH, the 2528 bytes consumed by these functions (nearly 2.5 KB), is quite significant!
A quick search revealed that these functions are double-precision math routines. Why were we using double-precision? I can think of two reasons:
- In the C programming language, all floating point constant literals are assumed to be double-precision unless specifically made single-precision by appending f. For example, 1.0 is a double-precision constant literal whereas 1.0f is a single-precision one. I have known about this for many years and was therefore careful to use only single-precision by ensuring that all constant literals had the requisite f. But it turns out that this was not enough.
- Another property of the C programming language is that implicit conversions from integer to floating point types automatically convert the values to double-precision. Any operations on those values will then proceed in double-precision and may incur even more penalty for conversion to single-precision!
It turns out that the second one was the culprit here. Indeed, the code did contain some implicit conversions from integer to floating point types.
I could hunt down all possible expressions that were doing this and write them with explicit typecasts to (float) but that presented the following disadvantage: any modification to the code in the future might reintroduce this issue. I wanted a solution that would avoid any future regressions.
GCC options to the rescue! It turns out that GCC has a compiler option, -fsingle-precision-constant, which avoids that implicit promotion. Note, however, that this may cause single-precision constants to be used in operations on double-precision values. In this particular application, this potential drawback is not an issue, since I intend to use only single-precision floating point math.
The GCC Wiki page on floating point math contains much more information about the topic of floating point.
After:
After specifying this setting in the project's build settings (under C/C++ Build → Settings → MCU GCC Compiler → Miscellaneous → Other flags), this is the summary:

RAM usage is unchanged from 4.93% since we did not modify any statically allocated variables, but note that the FLASH usage has reduced from 24.22% to 20.62%. We succeeded to knock off almost a handful of percentage points just by specifying one compiler option.
References and External Resources
Send feedback to: the name of this blog at mail dot com.